AI Hardware
Small Computers
Open Interpreter is a Linux open source project that combines the 01 Light ESP32-based voice computer with an LLM backend. All source code is available on GitHub.
Run Stable Diffusion on a Raspberry Pi
and GPU-Accelerated LLM on a $100 Orange Pi
> 100 Orange Pi 5 with Mali GPU, we achieve 2.5 tok/sec for Llama2-7b and 5 tok/sec for RedPajama-3b through Machine Learning Compilation (MLC) techniques. Additionally, we are able to run a Llama-2 13b model at 1.5 tok/sec on a 16GB version of the Orange Pi 5+ under $150.
Which GPU?
$23,000 CPU: Prodigy Universal Processor is planned for release later this year as a CPU, GPU, and TPU in a single unit. The 192-core 5nm processor claims 4.5 times the performance for cloud workloads, and 3x GPUs for high-performance computing (HPC), and 6x than AI application GPUs.
Cloud GPU Guide explains the difference among GPUs
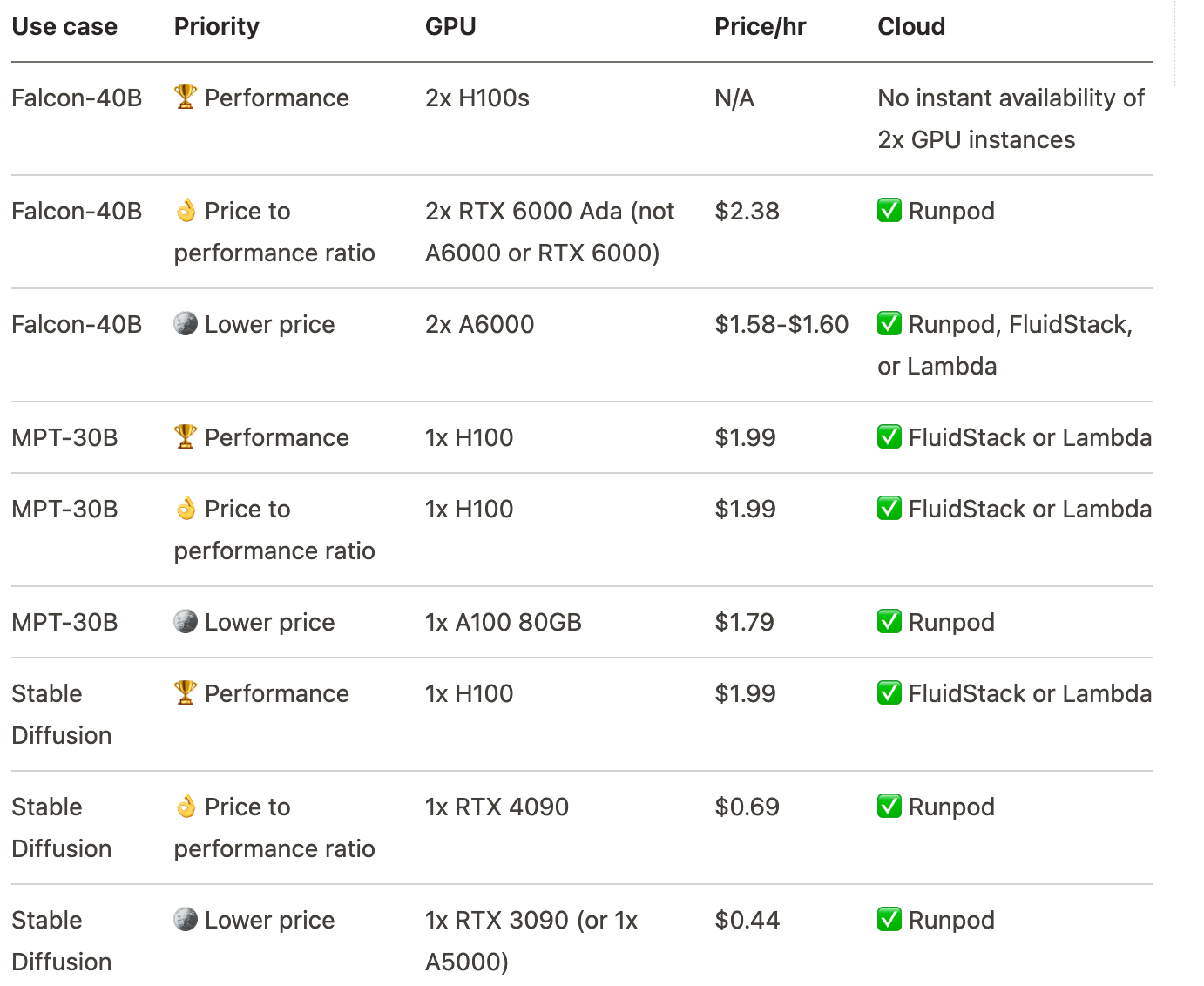 The full site gives many more details described in succinct, technical language.
The full site gives many more details described in succinct, technical language.
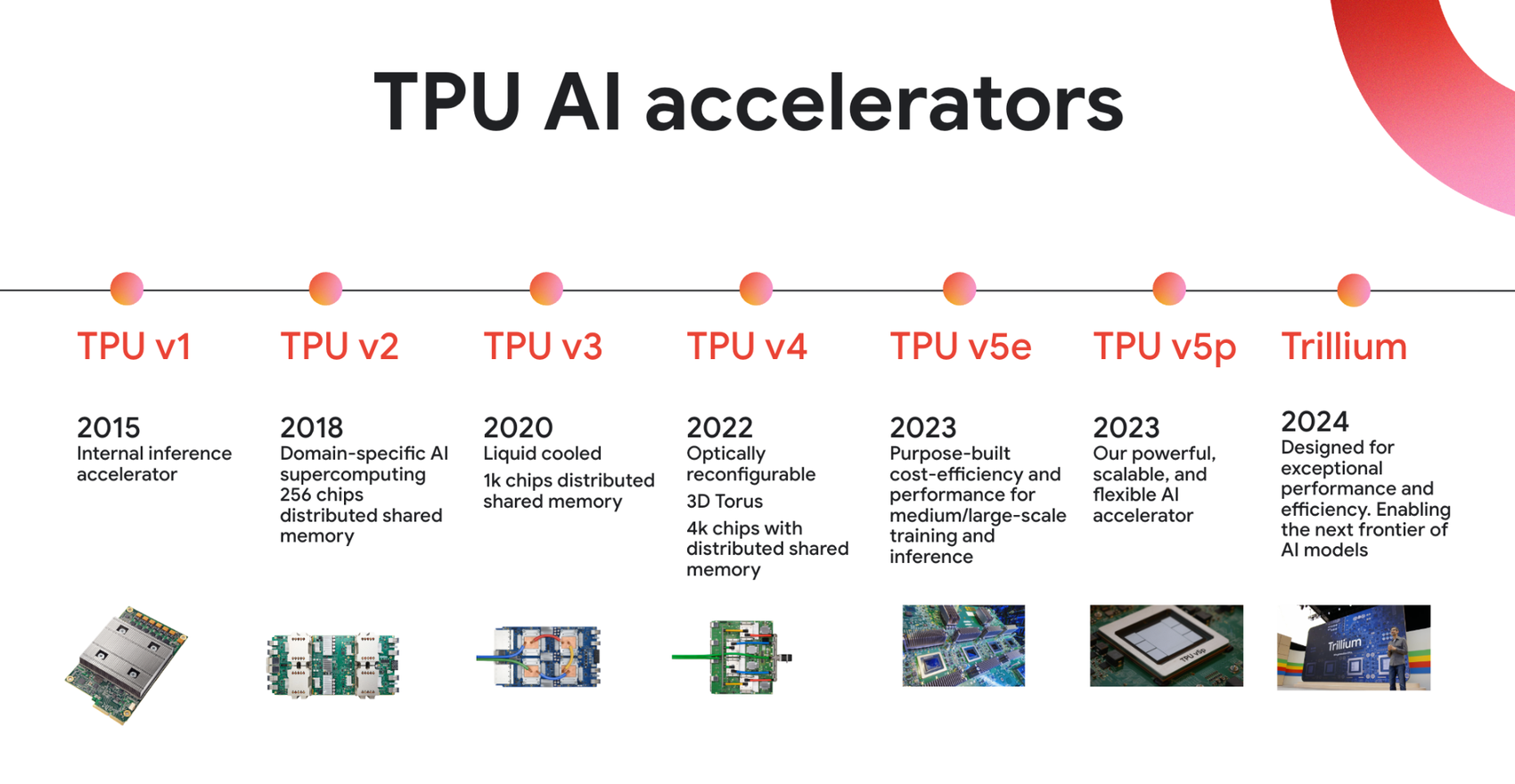
Google TPU
Google’s description of its TPU
Today, Anthropic, Midjourney, Salesforce, and other well-known AI teams use Cloud TPUs intensively. Overall, more than 60% of funded generative AI startups and nearly 90% of gen AI unicorns use Google Cloud’s AI infrastructure, including Cloud TPUs.
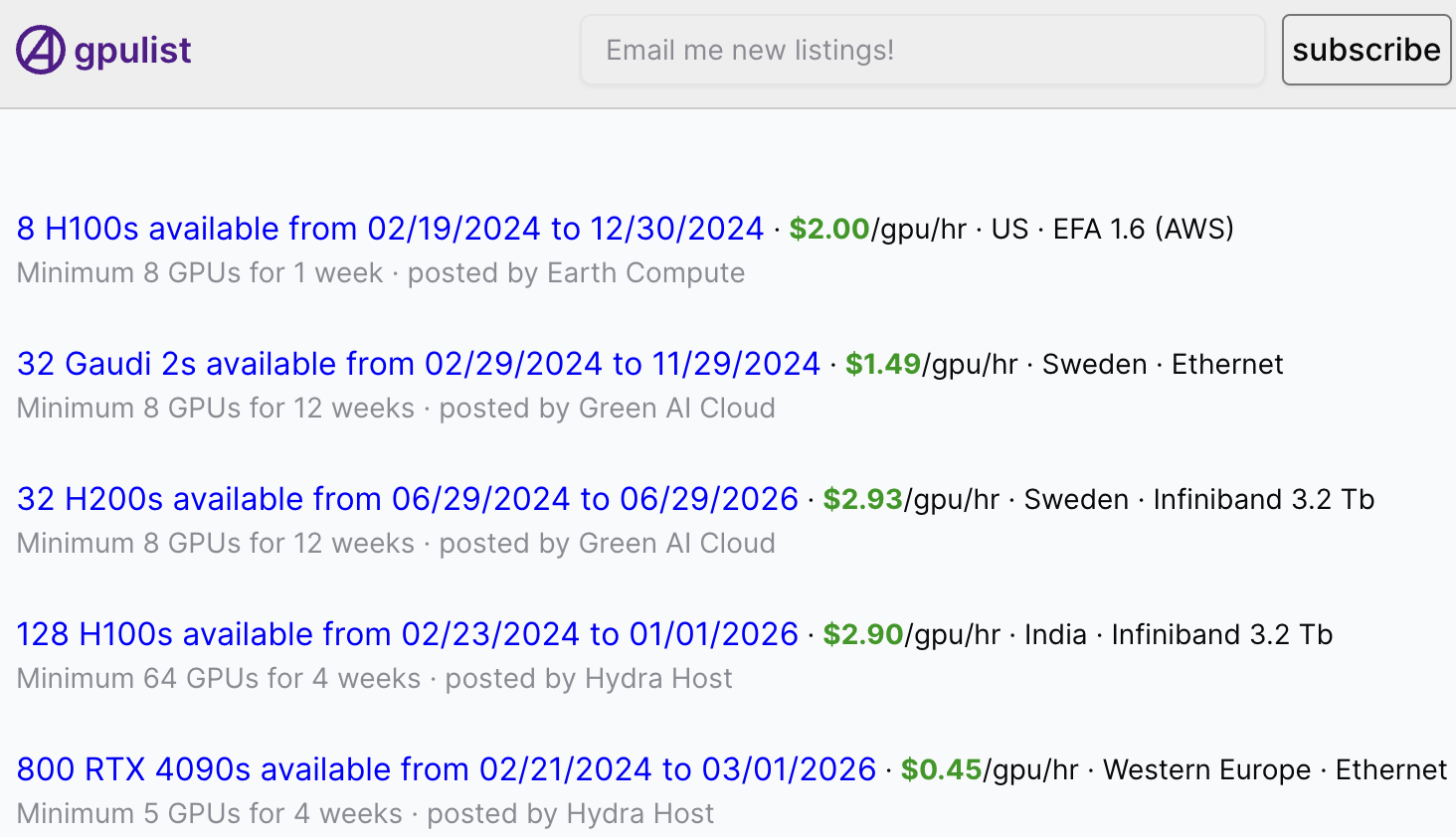
Renting a GPU
Looking to rent a GPU? GPUlist lists available clusters worldwide and their prices per hour.
Challenges
Seminalysis does a breakdown on the challenges LLMs bring to the traditional TPU or GPU-based hardware for previous generations of AI.
Google has a near-unmatched ability to deploy AI at scale reliably with low cost and high performance….We believe Google has a performance/total cost of ownership (perf/TCO) advantage in AI workloads versus Microsoft and Amazon due to their holistic approach from microarchitecture to system architecture. The ability to commercialize generative AI to enterprises and consumers is a different discussion.
and it’s hitting a brick wall
The most well-known models, such as GPT, BERT, Chinchilla, Gopher, Bloom, MT-NLG, PaLM, and LaMDA, are transformers. Transformers are a type of multi-layer perceptron (MLP) network and are generally considered dense matrix models. Dense models are fully connected, with all “neurons” in one layer connecting to all “neurons” in the next layer. This allows the model to learn complex interactions between the features and learn non-linear functions.
Training costs
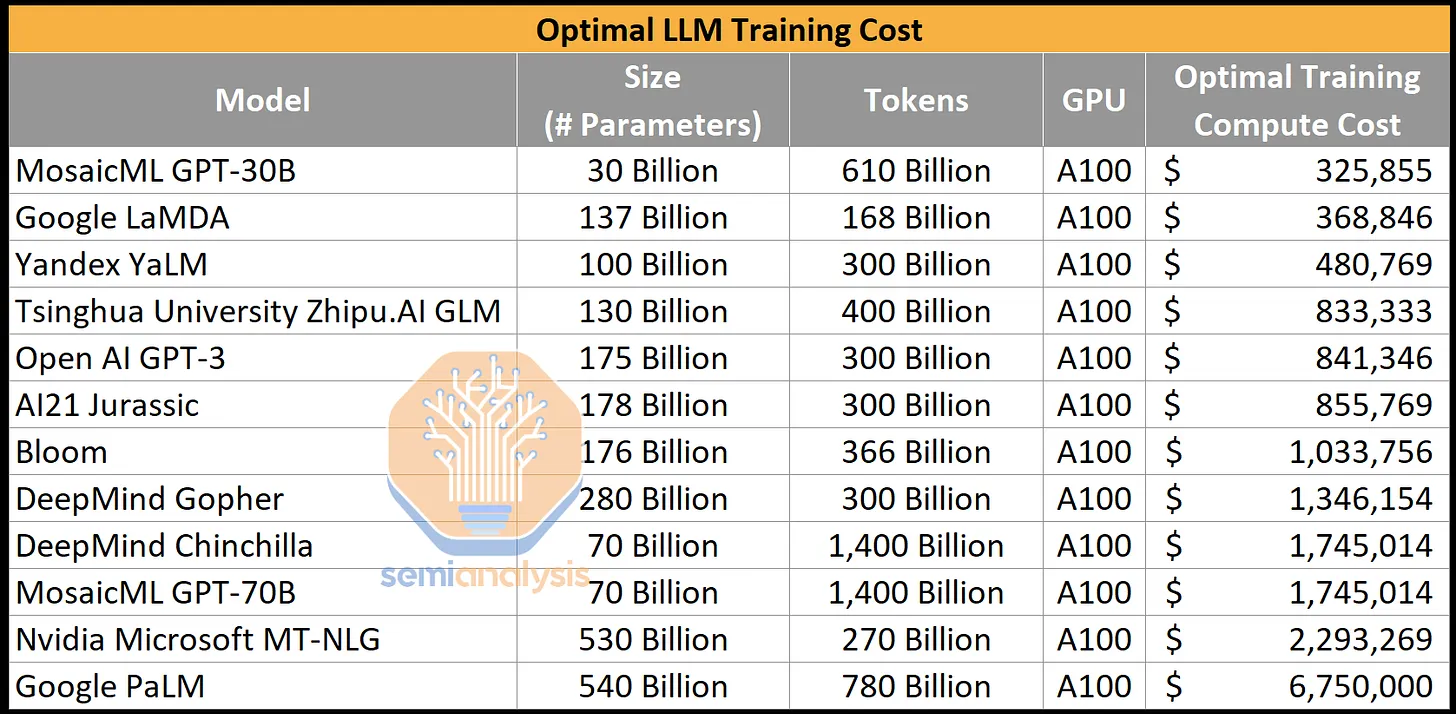
10 Trillion parameter models would cost $30 billion using existing technology.
Sohu Transformer Chip
From Etched is a specialized ASIC (not a GPU) built just for transformers, and is much faster.
-p-500.png)
Biological Computers
FinalSpark is a Swiss company that makes biological neurons (“brain organoids”) that you can rent for $500/hour.
see LiveScience
Watch a livestream